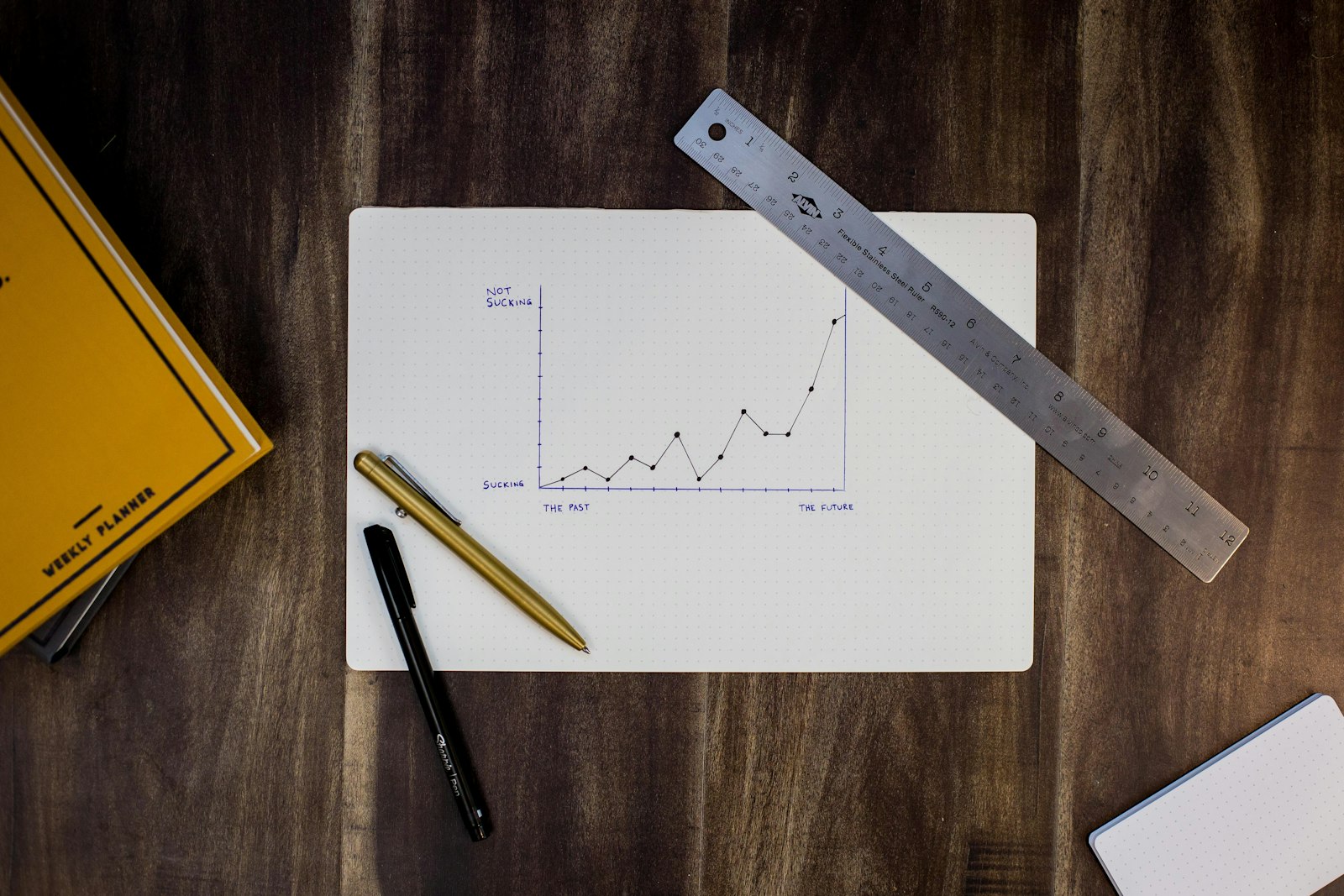
Your data stack isn't slow. It's lying to you.
Dashboards refresh. Numbers look fine. Underneath, four failures compound silently until the board meeting where the revenue number is wrong.
Schema Drift Kills Production
Source system adds a column. Downstream model casts the wrong type. Revenue dashboard is off by 12% for three weeks before anyone notices. Without schema contracts and lineage, every source change is a silent landmine.
Pipelines Fail Silently
Airflow job marked green. No rows actually loaded. No alert fired because nobody set an SLO on row count. Your finance team builds Q3 forecasts on a table that hasn't updated since Q2.
Dashboards Stale By Lunch
Nightly batch runs at 2am. By 11am the ops team is making decisions on 9-hour-old data. Real-time was never the goal but neither was a 12-hour gap between event and insight.
Governance Is Compliance Theatre
PII columns scattered across 40 tables. No lineage. No catalog. Audit week arrives and three analysts spend two months reverse-engineering data flows. Governance bolted on after the fact never holds up.
Six modules. Every one running in production.
Fixed-scope engagements. Real timelines. Real price floors. No retainer roulette.
Pipeline Engineering
ELT pipelines that actually hold. Airflow or Dagster orchestration, dbt models, Fivetran or custom connectors. SLO-driven, alerting on row counts and freshness, not just job status. 6-10 weeks · Starts at $30K.
Warehouse Architecture
Snowflake, BigQuery, or Databricks chosen against your actual workload, not the vendor that bought lunch. Layered modeling (staging / intermediate / marts), incremental strategy, cost-aware compute. 8-14 weeks · Starts at $40K.
Real-Time Streaming
Kafka, Kinesis, or Spark Streaming. CDC from Postgres/MySQL/MongoDB into the warehouse with sub-minute lag. We pick streaming when it earns its cost never just to ship a roadmap bullet. 8-12 weeks · Starts at $45K.
Data Observability
Freshness SLOs, row-count alerts, schema-drift detection, lineage. Monte Carlo, Datadog, or custom on OpenTelemetry built so your team sees breakage before the CFO does. 4-8 weeks · Starts at $20K.
BI & Visualization
Looker, Tableau, or Metabase wired to a clean semantic layer. Metrics defined once, used everywhere. No more two analysts producing two different revenue numbers in the same week. 4-8 weeks · Starts at $20K.
ML Data Layer
Feature stores, vector DBs, embedding pipelines for the data products that actually justify ML. Feast, Tecton, Pinecone, Weaviate wired to the same warehouse the rest of the org uses. 6-12 weeks · Starts at $35K.
Four principles. Non-negotiable.
We bring the same standard we applied to industrial AI telemetry at Tata Steel 10TB+/day, zero silent failures to every data build.

Pipelines as Products
Every pipeline has an owner, an SLO, a runbook, and a contract with its consumers. Not a folder of cron jobs nobody understands. Treat data like software or watch it rot.
Observability Before Volume
We don't ship a pipeline until freshness, row counts, and schema are monitored. Scaling a blind system is just compounding the silent failures.
Fixed-Scope Builds
Every module ships against a fixed scope, fixed timeline, fixed price floor. You always know what you're buying. We always know what we're shipping.
Lineage From Day One
Column-level lineage and a catalog ship with the warehouse not bolted on the week before the audit. Governance is an architecture decision, not a procurement deliverable.
Trusted by heads of data shipping production pipelines across fintech, industrial AI, and B2B SaaS.
What we build with. All production-proven.
- Snowflake
- BigQuery
- Databricks
- Airflow
- dbt
- Fivetran
- Kafka
- Kinesis
- Spark
- Monte Carlo
- Datadog
- Grafana
Business outcomes, not pipeline diagrams.
- dbt models
- Materialized views
- Incremental loads
- Catalog
- RBAC
- Audit logs
- Kafka
- CDC
- Streaming SQL
- Workload tuning
- Reservation
- Query pruning
Three outcomes that justify the spend.
When the CFO asks why this engagement matters, here's what you point to. Not pipelines P&L movements you can defend in any quarterly review.


12 weeks. Discovery to production.
Discovery
Current-state audit, source inventory, SLO definition, governance scope. You leave week 2 with a fixed-scope spec and a fixed price.
Architecture
Warehouse and pipeline design, lineage plan, observability stack, security model. The shape of the system is locked before any data moves.
Build
Pipelines ship to production weekly. Every Friday demo is real data flowing into real tables not a slide deck.
Ship
Observability live, alerts tuned, runbooks delivered, on-call training done. Your team takes the keys.
Hard questions. Straight answers.
The questions every Head of Data actually asks before signing.
Talk to Data EngineeringQ.01What does this cost?
Q.02Do you work with our existing stack?
Q.03How do you handle governance and compliance?
Q.04Real-time or batch how do you decide?
Q.05What about ML readiness?
Q.06Who owns the result?
Build data pipelines that don't break. at 3am or any other hour.
If you're tired of pipelines that fail silently and dashboards that lie, let's talk. Senior data engineers only. Fixed-scope. Production-first.